
随着ChatGPT的火爆出圈,为大语言模型的场景化落地提供了肥沃的土壤。目前,医疗、教育、金融领域已逐渐有了各自的模型,但法律领域相关的产品却不是很多。
因此,北大团队开源了中文法律大模型,并针对大语言模型和知识库的结合问题给出了法律场景下合理的解决方案。
目前,ChatLaw法律大模型提供ChatLaw-13B、ChatLaw-33B和ChatLaw-Text2Vec三个版本,底座为姜子牙-13B、Anima-33B。使用了大量法律新闻、法律论坛、法条、司法解释、法律咨询、法考题、判决文书等原始文本来构造对话数据。
ChatLaw-13B:此版本为学术demo版,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
ChatLaw-33B:此版本为学术demo版,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
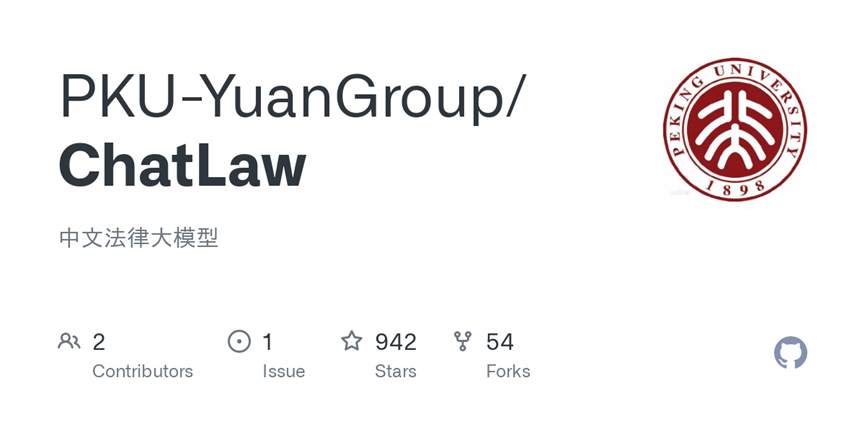
ChatLaw-Text2Vec:使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配。例如,请问如果借款没还怎么办?
ChatLaw的回答:合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还。
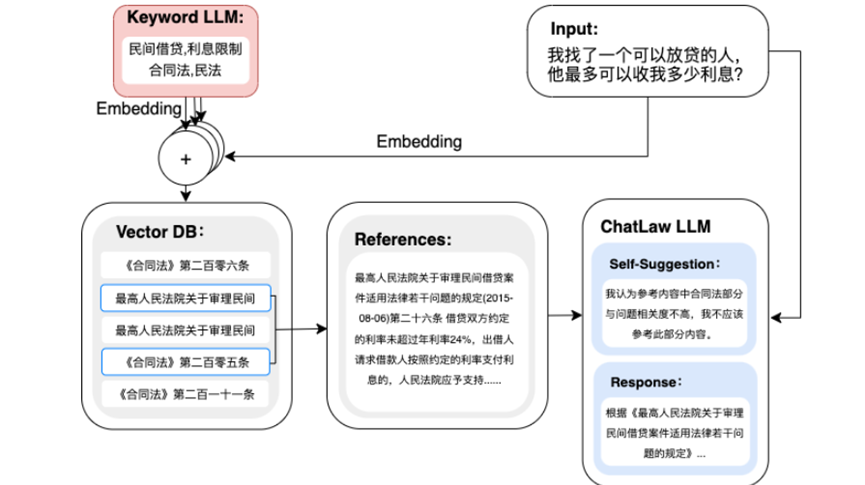
产品效果体验
「AIGC开放社区」通过免费无需注册的在线体验地址(https://chatlaw.cloud/lawchat/#/)使用了ChatLaw,其表现出来的法律效果要比同类产品更加专业、垂直,同时支持多轮对话交互。(暂未接入专业法律咨询功能)
例如,夫妻离婚,有哪些需要注意的法律问题?
ChatLaw:离婚是一项非常严肃和复杂的决定,需要仔细考虑以下几个方面的法律问题。
1.财产分割:在离婚过程中,夫妻双方应该协商如何处理共同拥有的财产。这包括房屋、车辆、银行账户等资产。如果无法达成协议,法院将会根据当地的法律规定进行裁决。
2.子女抚养权:如果夫妻有未成年子女,他们必须就子女的抚养权达成协议。这可能涉及到探视权、监护权、支付赡养费用等问题。如果无法达成协议,法院将会根据当地的法律规定进行裁决。
3.债务分担:在离婚过程中,夫妻双方应该协商如何处理共同负担的债务。例如信用卡欠款、贷款等。如果无法达成协议,法院将会根据当地的法律规定进行裁决。
4.保险政策:在离婚过程中,夫妻双方应该讨论如何处理共同购买的保险政策。例如人寿保险、医疗保险等。如果无法达成协议,法院将会根据当地的法律规定进行裁决。
5.遗嘱:在离婚过程中,夫妻双方应该讨论如何更新或撤销共同制定的遗嘱。如果无法达成协议,法院将会根据当地的法律规定进行裁决。
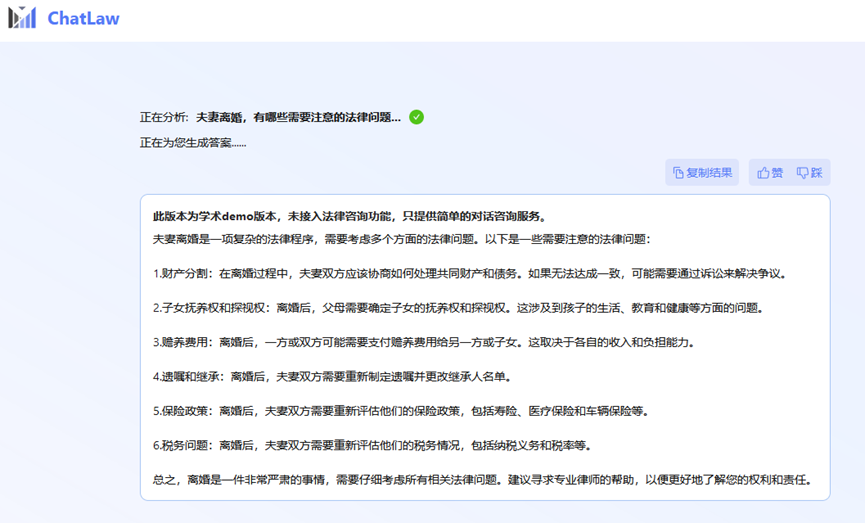
实验结果
如何合理地评估垂直领域大模型的性能一直是一个问题,因为测试数据和真实场景存在差异。北大团队只是收集了十余年的国家司法考试题目,整理出了一个包含2000个问题及其标准答案的测试数据集,用以衡量模型处理法律选择题的能力:评测数据demo。
然而,开发团队发现各个模型的准确率普遍偏低。在这种情况下,仅对准确率进行比较并无多大意义。因此,借鉴英雄联盟的ELO匹配机制,做了一个模型对抗的ELO机制,以便更有效地评估各模型处理法律选择题的能力。以下分别是ELO分数和胜率图
得到以下结论:
(1)引入法律相关的问答和法规条文的数据,能在一定程度上提升模型在选择题上的表现。
(2)加入特定类型任务的数据进行训练,模型在该类任务上的表现会明显提升。例如ChatLaw模型之所以能胜过GPT-4,是因为使用了大量选择题作为训练数据;
(3)法律选择题需要进行复杂的逻辑推理,因此,参数量更大的模型通常表现更优。
未来发展计划
提升逻辑推理能力,训练30B以上的中文模型底座:在ChatLaw的迭代过程中,发现和医疗、教育、金融等垂直领域不同的是,法律场景的真实问答通常涉及很复杂的逻辑推理,这要求模型自身有很强的逻辑能力,预计只有模型参数量达到30B以上才可以。
安全可信,减少幻觉:法律是一个严肃的场景,我们在优化模型回复内容的法条、司法解释的准确性上做了很多努力,现在的ChatLaw和向量库结合的方式还可以进一步优化,另外和ChatExcel团队师兄深度结合,在学术领域研究LLM的幻觉问题,预计两个月后会有突破性进展,从而大幅减轻幻觉现象。
私有数据模型:一方面会继续扩大模型的基础法律能力,另一方面会探索B/G端的定制化私有需求。



