
你没看错,无需任何服务器,只用一个浏览器就能运行类ChatGPT大语言模型。
WebLLM采用的是Web GPU加速技术,还为TVM支持的其他类型的GPU后端(例如,CUDA、OpenCL 和 Vulkan)提供了线束。这使得没有庞大GPU资源的中小企业、个人开发者,在不需要算力成本的情况下,可以轻松探索类ChatGPT大语言模型的功能。
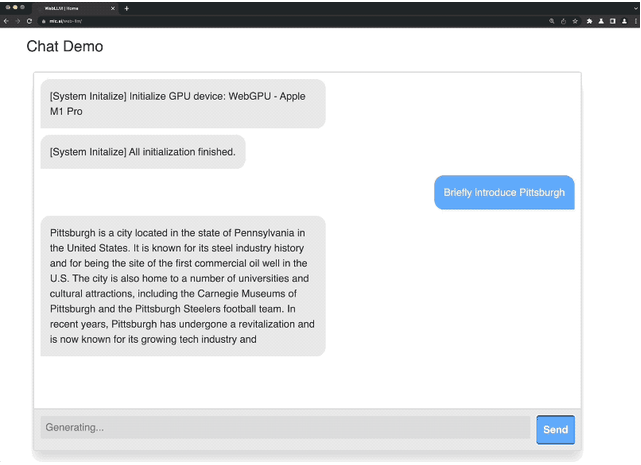
根据微软最新公布的数据显示,ChatGPT每天的算力成本在70万美元。这对于中小型企业、个人开发者而言要搭建像ChatGPT那样1750亿参数的大语言模型几乎不可能。
不过,经过学术研究机构、企业的共同努力出现了LLaMA、Alpaca、Vicuna和Dolly 2.0等资源消耗低性能强悍的类ChatGPT开源项目,但依然对算力要求很高想运行起来并不容易。现在,通过一个浏览器就能使用Web LLM。
Web LLM技术原理
从Web LLM描述文档来看,该项目的核心之一是使用Apache TVM Unity 的机器学习编译,通过原生动态形状支持来优化语言模型的IRModule 而无需填充。其解决方案由多个开源项目组成,包括LLaMA、Vicuna、Wasm和WebGPU。主要流程建立在 Apache TVM Unity 之上,优化功能如下:
Web LLM在具有原生动态形状支持的 TVM 中烘焙语言模型的IRModule,避免了填充到最大长度的需要,并减少了计算量和内存使用量。
-
TVM的IRModule 中的每个函数都可以进一步转换并生成可运行的代码,这些代码可以普遍部署在最小tvm运行时(JavaScript 是其中之一)支持的任何环境中。 -
TensorIR是用于生成优化程序的关键技术。Web LLM通过结合专家知识和自动调度程序快速转换 TensorIR 程序来提供高效的解决方案。 -
启发式算法用于优化轻量级运算符以减轻工程压力。 -
Web LLM利用int4量化技术来压缩模型权重以便适合内存。 -
Web LLM构建静态内存规划优化以跨多个层重用内存。 -
Web LLM使用Emscripten和 TypeScript 构建一个可以部署生成的模块的 TVM web 运行时,还利用了SentencePiece分词器的wasm端口。 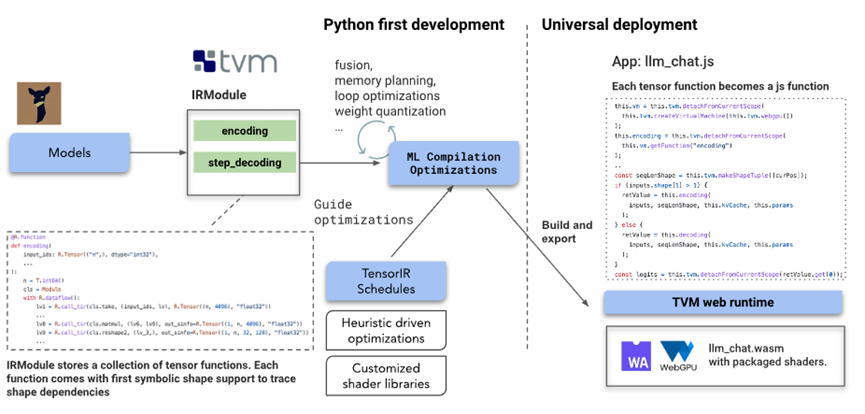 此外,大语言模型的一个关键特征是模型的动态特性。由于解码和编码过程依赖于随着令牌大小而增长的计算,Web LLM利用 TVM 统一中一流的动态形状支持,通过符号整数表示序列维度。
此外,大语言模型的一个关键特征是模型的动态特性。由于解码和编码过程依赖于随着令牌大小而增长的计算,Web LLM利用 TVM 统一中一流的动态形状支持,通过符号整数表示序列维度。
这使Web LLM能够提前计划静态分配感兴趣的序列窗口,所需的所有内存而无需填充。
可切换模式
Web LLM除了提供WebGPU,还支持使用本地 GPU 运行时进行本地部署的选项。因此它们既可以用作在本机环境上部署的工具,也可以用作比较本机GPU驱动程序性能和 WebGPU 的参考。
值得一提的是,Web LLM的主要开发者是陈天奇团队。陈天奇是机器学习领域著名的青年华人学者之一,本科毕业于上海交通大学ACM班,博士毕业于华盛顿大学计算机系,研究方向为大规模机器学习。
同类产品Window AI
4月23日也有一款通过浏览器运行ChatGPT等大语言模型的产品Window AI。
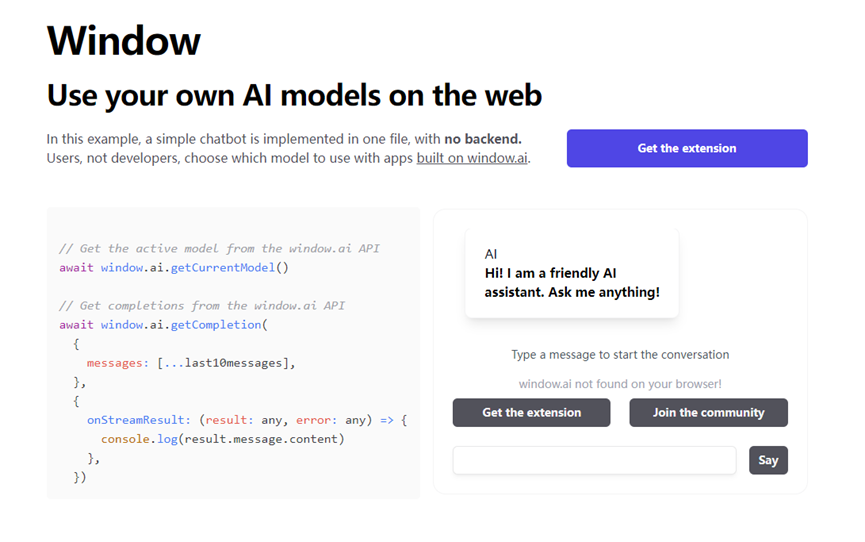
Window AI支持GPT-3.5、GPT-4、Open ChatKit、Xlarge等大语言模型的运行,用户只需要密钥或进行本地配置连接就能在浏览器中运行大语言模型。所以,Window AI更像是一个“ChatGPT模型整理箱”,可以根据不同的需求切换模型。

目前,Window AI也做成了插件形式,可以在谷歌浏览器商店使用它。



