虽然提示工程的原则可以在许多不同的模型类型间归纳,但某些模型需要专用的提示结构。对于 Azure OpenAI GPT 模型,目前有两个不同的 API,提示工程可以在其中发挥作用:
- 聊天补全 API。
- 补全 API。
每种 API 要求以不同的格式输入数据,这反过来又会影响整体的提示设计。聊天补全 API 支持 ChatGPT(预览版)和 GPT-4(预览版)模型。这些模型旨在接收存储在字典数组中的类似聊天的特定脚本格式的输入。
补全 API支持较旧的 GPT-3 模型,并且具有更灵活的输入要求,即它接受没有特定格式规则的文本字符串。从技术上讲,ChatGPT(预览版)模型可与任一 API 一起使用,但我们强烈建议对这些模型使用聊天补全 API。若要了解更多,请参阅使用这些 API 的深入指南。
本指南中的技术将指导你提高使用大型语言模型 (LLM) 生成的响应的准确性和基础。但是,请务必记住,即使有效地使用了提示工程,你仍需要验证模型生成的响应。仅仅因为精心制作的提示适用于某个特定方案并不一定意味着它能更广泛地推广到某些用例。了解LLM 的限制与了解如何利用其优势一样重要。

系统消息
系统消息包含在提示的开头,用于为模型提供上下文、说明或与用例相关的其他信息。可以使用系统消息来描述助手的个性,定义模型应回答和不应回答的内容,以及定义模型响应的格式。
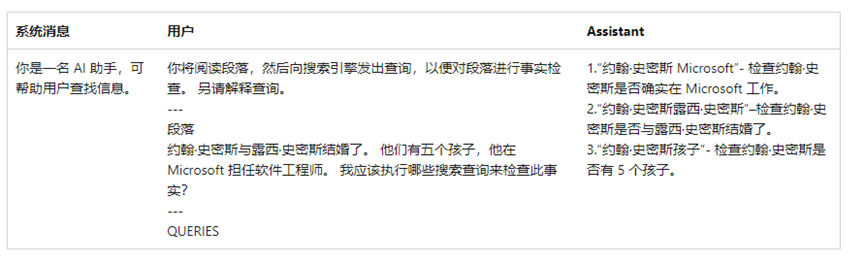
下面的示例显示了示例系统消息和生成的模型响应:

系统消息的其他一些示例包括:
“助手是由 OpenAI 训练的大型语言模型。”
“助手是一种智能聊天机器人,旨在帮助用户回答有关Azure OpenAI 服务的技术问题。仅使用以下上下文回答问题,如果不确定答案,可以说“我不知道”。
“助手是一种智能聊天机器人,旨在帮助用户回答其税务相关问题。”
“你是一名助手,旨在从文本中提取实体。用户将粘贴文本字符串,你将使用从文本中提取的实体作为 JSON 对象进行响应。下面是输出格式的示例:

少样本学习
使语言模型适应新任务的一个常见方法是使用少样本学习。在少样本学习中,需要在提示中提供一组训练示例,以便为模型提供额外的上下文。
使用聊天补全 API 时,用户和助手之间的一系列消息(以新的提示格式编写)可以作为进行少样本学习的示例。这些例子可以用来引导模型以某种方式相应,模仿特定的行为,并为常见的问题提供种子答案。

非聊天场景
虽然聊天补全 API 已优化为处理多回合对话,但它也可用于非聊天场景。例如,对于情绪分析场景,可以使用以下提示:

从明确的说明开始
提示中显示信息的顺序很重要。这是因为 GPT 风格的模型是以某种方式构建的,这定义了它们处理输入的方式。我们的研究表明,在共享其他上下文信息或示例之前,在提示开始时告诉模型你希望它执行的任务有助于生成更高质量的输出。

在末尾重复指令
模型可能容易受到近因偏差的影响,在此上下文中,这意味着提示结束时的信息对输出的影响可能比提示开头的信息更大。因此,值得尝试的是,在提示结束时重复指令,并评估对生成的响应的影响。
引导输出
这是指在提示的末尾包含几个字词或短语,以获取遵循所需形式的模型响应。例如,使用“Here’s a bulleted list of key points:\n- ” 等提示有助于确保输出的格式为项目符号列表。

添加明确的语法
对提示使用明确的语法(包括标点符号、标题和节标记)有助于传达意向,并且通常使输出更易于分析。
在下面的示例中,分隔符(本例中为—)已添加到不同的信息源或步骤之间。这允许使用 — 作为生成的停止条件。此外,节标题或特殊变量以大写形式显示,用于区分。