
什么是RLHF
RLHF的英文为Reinforcement Learning with Human Feedback,中文译为“人类反馈强化学习”,是一种结合人类指导和自动强化学习的训练方法。人类通过对AI的行为进行评价或指导,帮助其在学习过程中做出更好的决策,优化输出内容。
由于人类可以通过直觉、视觉和实践经验等来帮助AI,因此,应用RLHF的产品可大幅度提升拟人化能力。
在ChatGPT等大语言模型的预训练过程中,RLHF在微调、优化输出、拟人化等方面发挥了巨大作用。很多开源大语言模型生成的文本内容非常生硬甚至有点“傻”,这是因为缺少RLHF的支持或核心训练数据不足。
简单来说,可以把RLHF看成是一种“妈妈教孩子”的的训练方法。AI相当于刚出生毫无经验的孩子,当它摔倒在地时,母亲(RLHF)会告诉他如何避免摔倒,以及更好地走路方法。AI可以在这种不断反馈的学习环境中快速成长,甚至自己学会跑步。
RLHF的4个流程
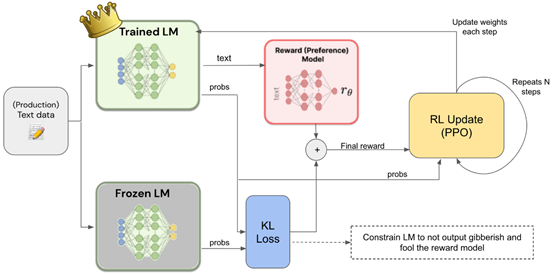
通常RLHF有无监督预训练、有监督的微调、奖励模型和基于奖励模型的强化学习4个流程组成。
无监督预训练:AI开始学习一个任务,可以采用随机的策略或基于某种启发式的策略。例如,从一个预训练好的语言模型GPT-3开始学习。
有监督的微调:AI在执行任务时,人类会对其行为进行评估。评估可以是连续的,例如,分数或奖励。也可以是离散的,例如,对某个行为是否正确的二元反馈。然后对预训练的模型进行微调,增强其拟人化能力。
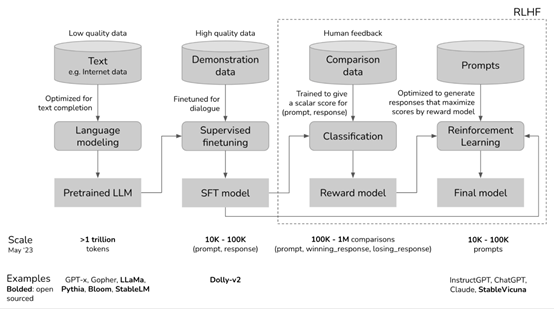
奖励模型:建立一个奖励模型对大语言模型的输出进行评分。AI根据人类的奖励反馈,会自动优化其策略,以便在未来的输出中更好地执行任务。
基于奖励模型的强化学习:AI会基于奖励模型不断地执行任务,接收人类反馈,并根据反馈更新其输出行为。这个过程会持续进行,直到AI的表现达到人类满意的水平。
虽然RLHF对于AI大模型来说好处很多,但中小型企业或普通开发人员想训练RLHF并不容易,对于谷歌、Meta这样的科技巨头也并非易事。
缺少真实、高质量人类训练数据是最大原因之一。而Prolific经营了一个超过12万人的社区,主要帮助AI大模型厂商提供真实训练数据、压力测试、在线调查等服务。(体验地址:https://www.prolific.co/)
Prolific提供真实、高质量训练数据
Prolific成立于2014年4月,总部位于英国牛津郡。创立至今Prolific仅获得了两次融资,2019年12月获得120万美元种子轮融资,另外一次受生成式AI风口影响,在今年7月12日获得的3200万美元融资。

经过多年的市场深耕,Prolific已获得了3000多家知名组织,其中包括谷歌、牛津大学、斯坦福大学、伦敦国王学院和欧盟委员会等。超过2万名科研人员在其平台上获取高质量数据。
截至目前,Prolific已经为12万社区人员支付了超过1亿美元的数据提供费用,每小时价格在6—8美元或更高。也就是说,Prolific提供的所有真实数据都是有版权的可以用于商业化。这一点对于大模型厂商来说非常重要,避免产生数据版权的纠纷。
前几天,谷歌就因为非法搜集用户数据用于训练AI模型,被美国加利福尼亚州克拉克森律师事务所起诉,要求向用户赔偿数据使用费和告知数据用途。

数据方面,Prolific保证提供的所有数据都是真人提供的,例如,所有参与者均通过Onfido 的银行级身份检查,以验证“人”是真实存在。
这12万人来自38个国家活跃度非常高。企业使用的方法也非常简单,只需要登录到Prolific平台,然后根据300多种数据过滤器创建多元化数据搜集任务,例如,科学、生活、文学、影视、农业等数据。然后启动订单,平均2小时左右就能完成数据集任务。

Prolific表示,高质量、真实训练数据对于AI大模型来说有减少幻觉、非法输出、增强RLHF能力、避免数据纠纷等诸多好处。其中,增强RLHF能力至关重要,在人类高度监督下AI可以极大提升内容的输出,例如,翻译模型将英语翻译为法语时,RLHF可提供专业翻译人员的建议,使得内容更加自然贴近真实。




