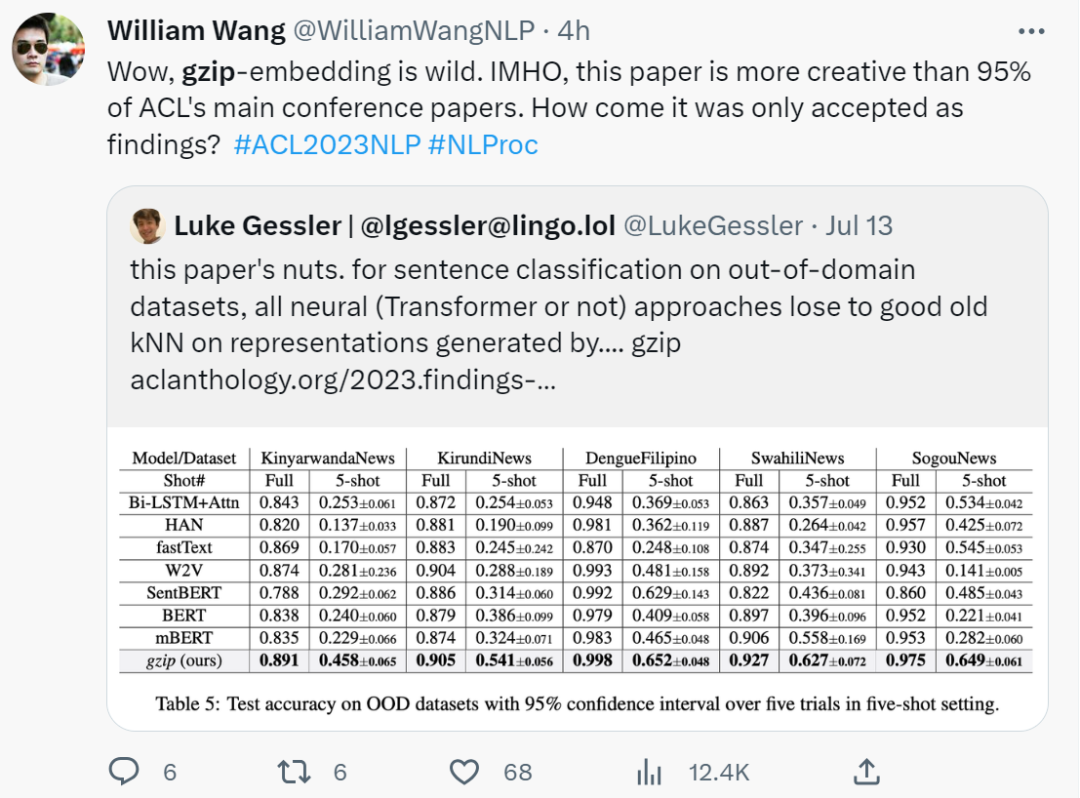
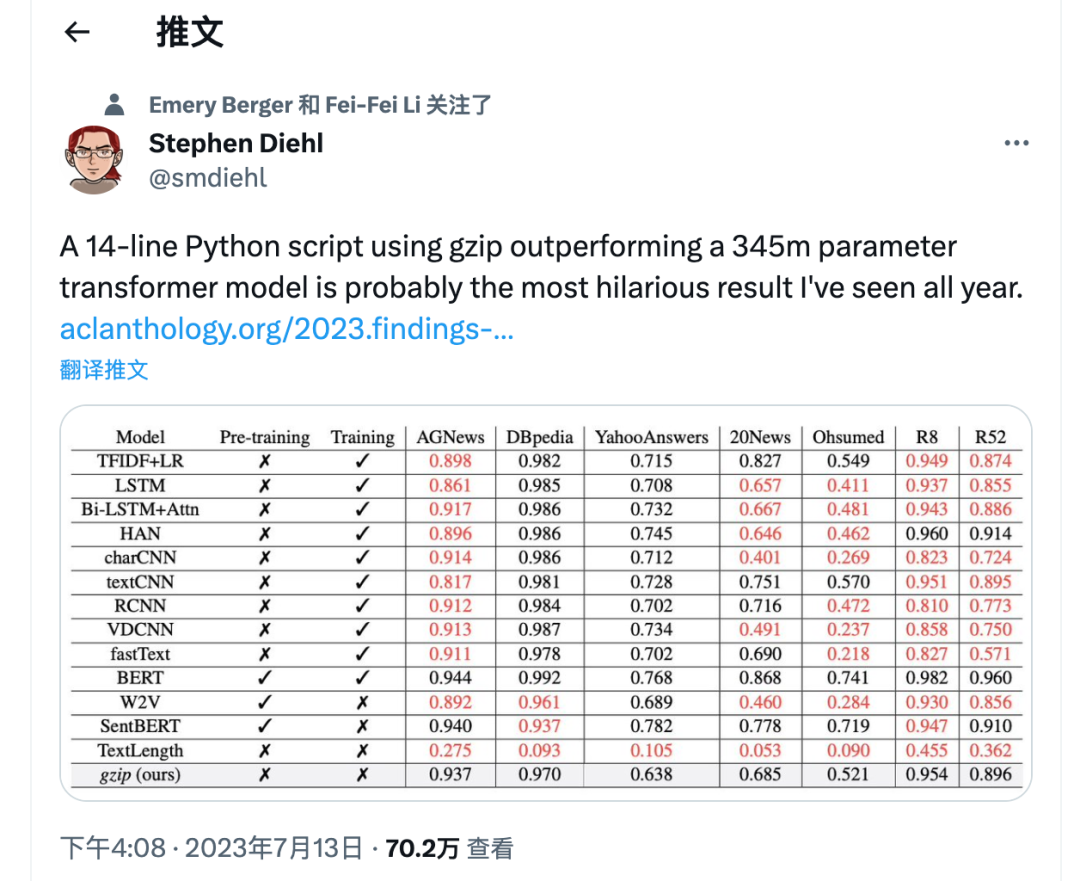
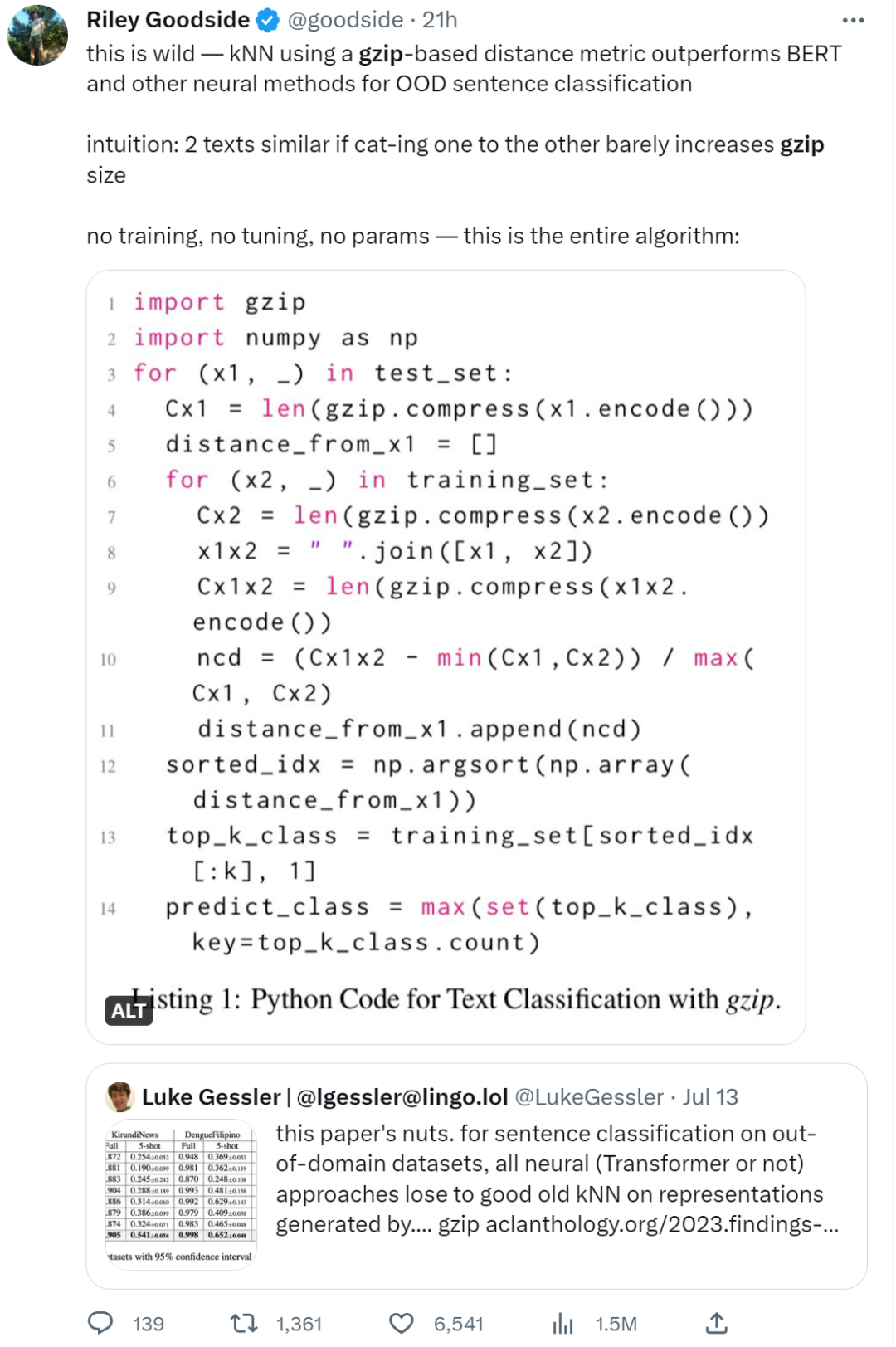
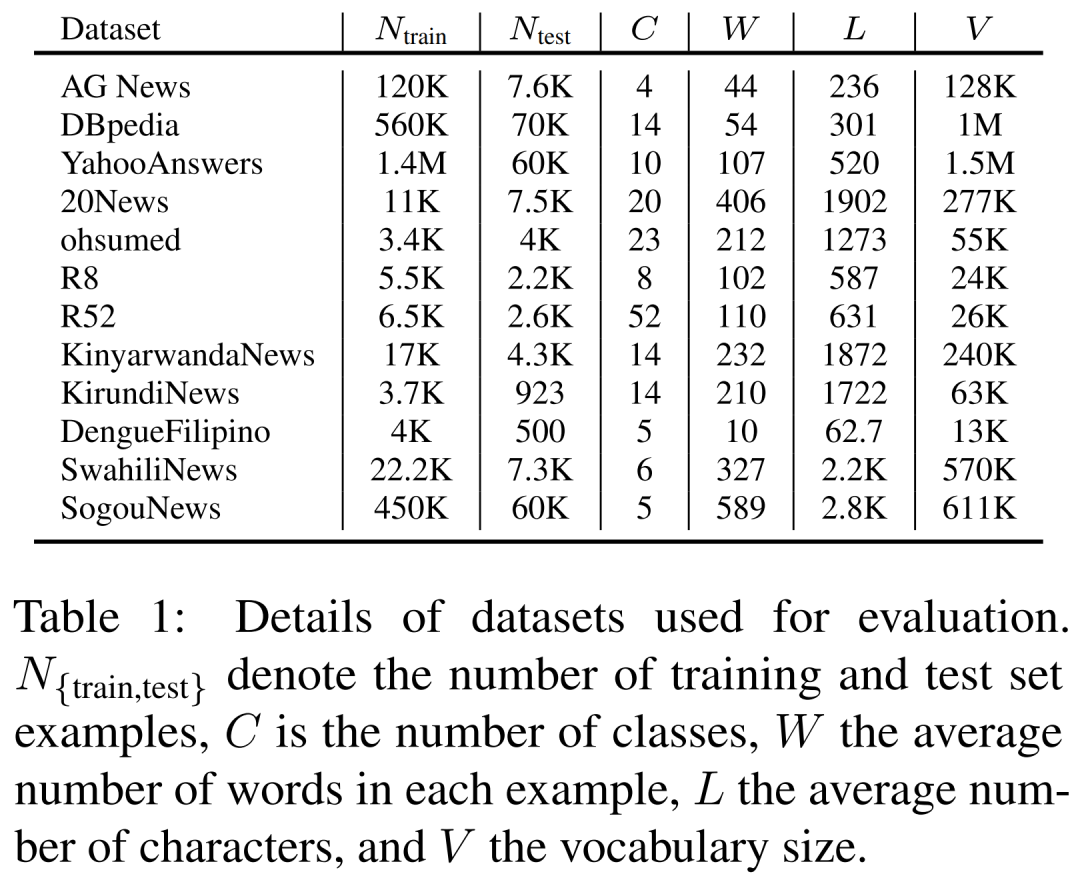
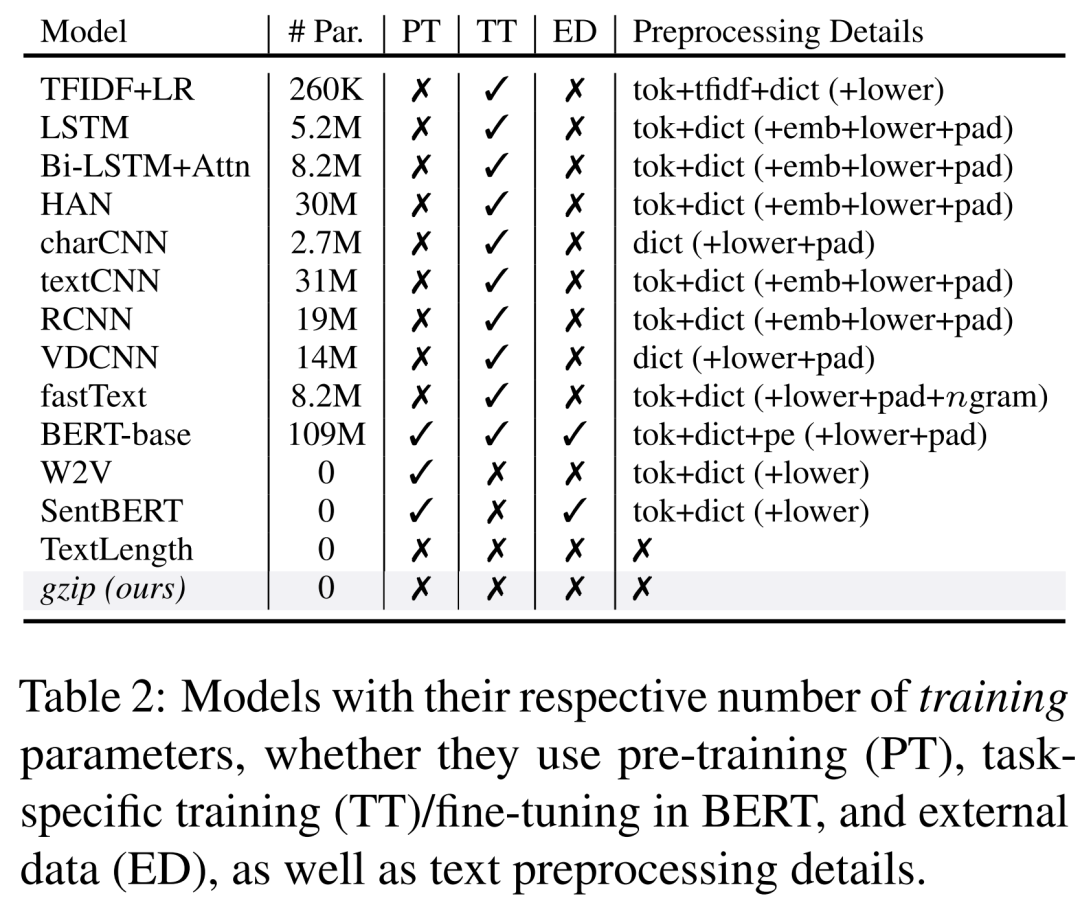
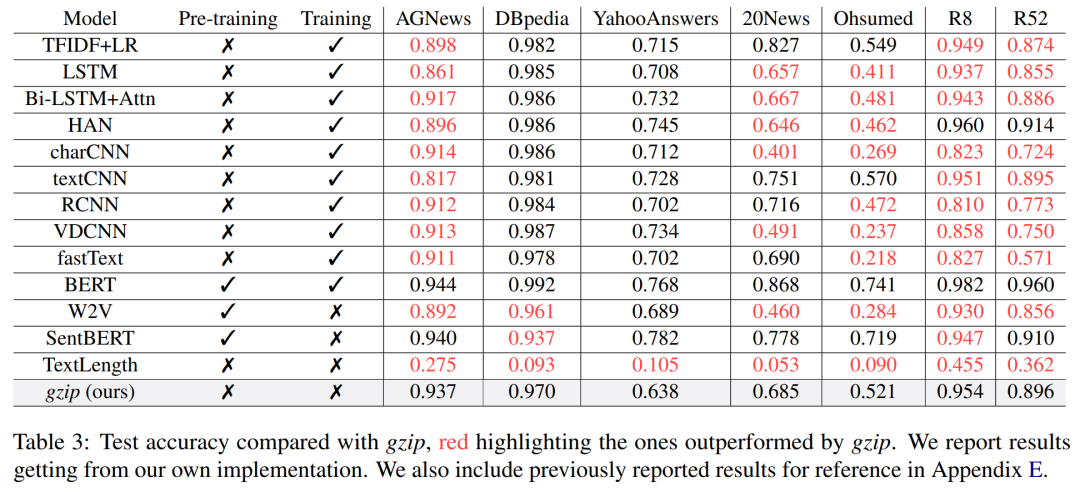
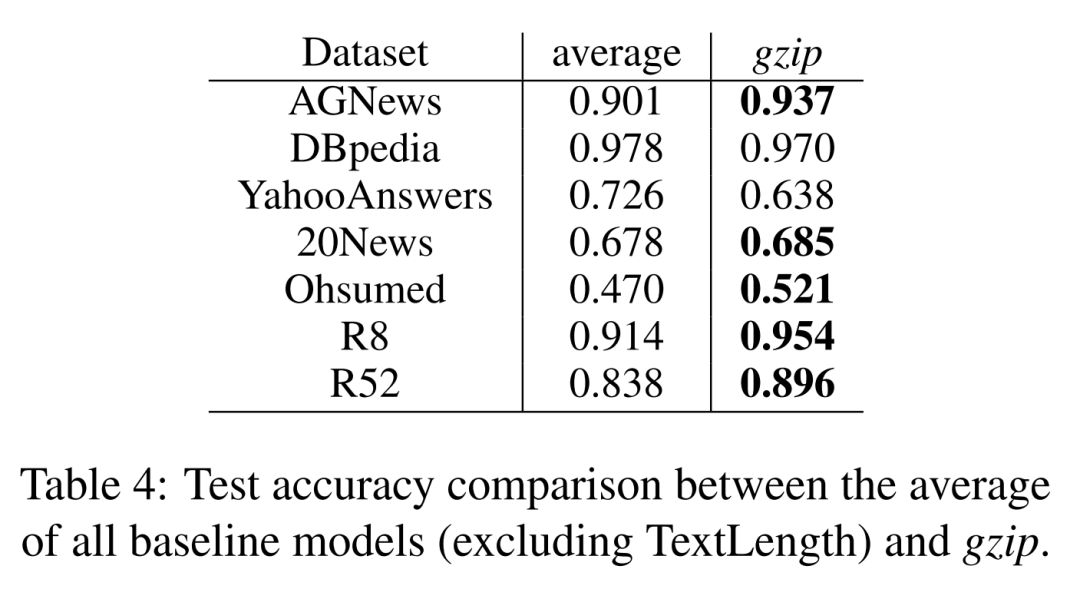
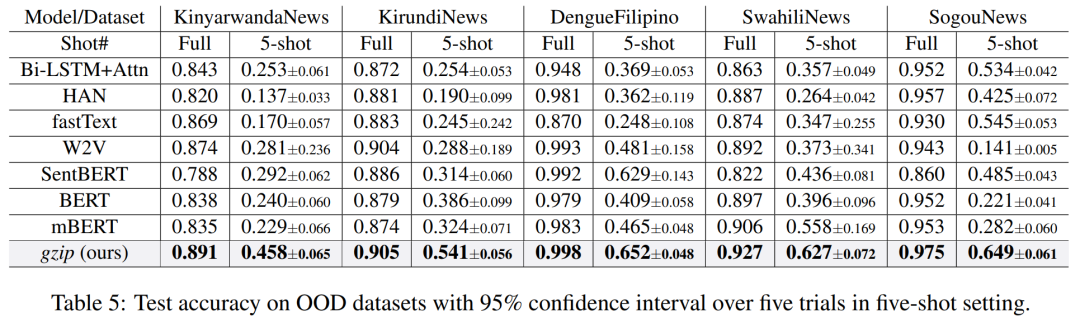
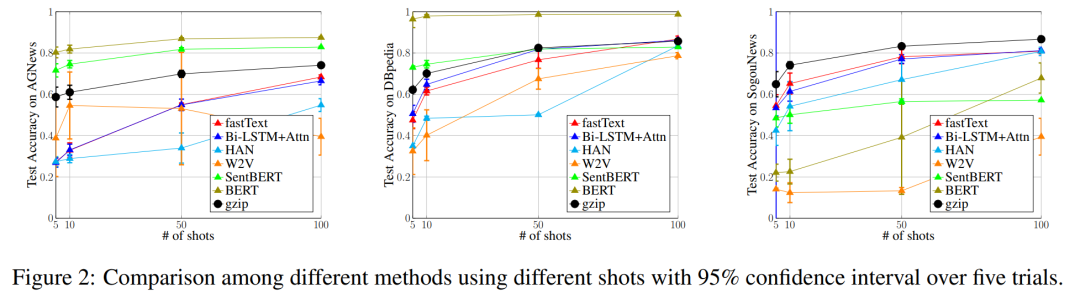
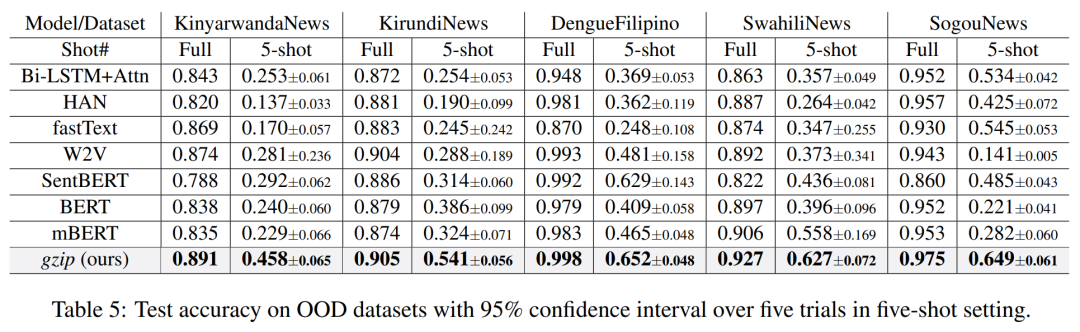
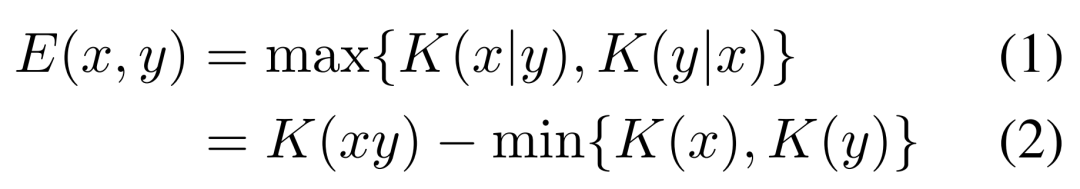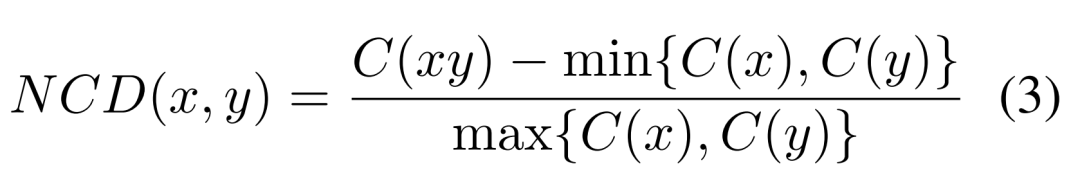当前位置: 首页干货分享正文 几天前,ACL 2023 大奖公布,引起了极大的关注。 但在众多收录的论文中,一篇名为《 “Low-Resource” Text Classification: A Parameter-Free Classification Method with Compressors 》的论文开始引起大家热议。这篇论文由滑铁卢大学、 AFAIK 机构联合完成,但既不是获奖论文更不是主会议论文。 论文地址:https://aclanthology.org/2023.findings-acl.426.pdf 代码地址:https://github.com/bazingagin/npc_gzip UCSB 助理教授王威廉形容这篇论文比 95% 的 ACL 主要会议论文更有创造性,因而不明白为什么只是作为 Findings 论文被录取: 也有网友称这是他今年见到最滑稽的结果: 这篇论文到底有何创新,得到大家如此的好评。接下来我们看看具体内容。 这篇文章主要是针对文本分类任务的。文中表示文本分类作为自然语言处理(NLP)中最基础的任务之一,在神经网络的帮助下取得了显著的改进。然而,大多数神经网络对数据的需求很高,这种需求随着模型参数数量的增加而增加。 在众多模型中,深度神经网络(DNN)由于准确率高,因此常常被用来进行文本分类。然而,DNN 是计算密集型的,在实践中使用和优化这些模型以及迁移到分布外泛化 (OOD) 的成本非常高。 研究者开始寻求替代 DNN 的轻量级方法,使用压缩器进行文本分类开始得到大家的关注。在这一领域,已经有研究者入局,但是,已有的方法在性能上还是无法与神经网络相媲美。 针对这一缺陷,本文提出了一种文本分类方法,他们将无损压缩器(如 gzip)与 k 最近邻分类器(kNN)相结合。 文中表示,采用这种方法在没有任何训练参数的情况下,他们在七个分布内数据集和五个分布外数据集上的实验表明,使用像 gzip 这样的简单压缩器,他们在七个数据集中的结果有六个与 DNNs 结果相媲美,并在五个分布外数据集上胜过包括 BERT 在内的所有方法。即使在少样本情况下,本文方法也大幅超越了所有模型。 网友也对这一结果感到惊讶,gzip+kNN 在文本分类任务中竟然胜过了 BERT 和其他神经网络方法。更令人意外的是这个算法没有训练过程、没有调优、没有参数 —— 有的只是 14 行代码,这就是整个算法内容。 方法概览 本文方法包含了一个无损压缩器、一个基于压缩器的距离度量以及一个 K 最近邻分类器。其中无损压缩器旨在通过将较短代码分配给概率更高的符号,来使用尽可能少的比特表示信息。 使用压缩器进行分类源于以下两个直觉知识:1)压缩器善于捕捉规律,2)同一类别的对象比不同类别的对象具有更强的规律性。 举例而言,下面的 x_1 与 x_2 属于同一类别,但与 x_3 属于不同类别。如果我们用 C (・) 来表示压缩长度,会发现 C (x_1x_2) − C (x_1) < C (x_1x_3) − C (x_1),其中 C (x_1x_2) 表示 x_1 和 x_2 串联的压缩长度。 这一直觉知识可以形式化为从柯尔莫哥洛夫(Kolmogorov)复杂度中导出的距离度量。为了测量两个对象之间共享的信息内容,Bennett 等研究人员在 1998 年发表的论文《Information distance》中将信息距离 E (x, y) 定义为将 x 转化成 y 的最短二进制程序的长度。 由于柯尔莫哥洛夫复杂度的不可计算性导致了 E (x,y) 不可计算,因而 Li et al. 在 2004 年的论文《The similarity metric》中提出信息距离的归一化和可计算版本,即归一化压缩距离(Normalized Compression Distance, NCD),它利用压缩长度 C (x) 来近似柯尔莫哥洛夫复杂度 K (x)。定义如下: 使用压缩长度的背后在于被压缩器最大化压缩的 x 的长度接近 K (x)。一般来说,压缩比越高,C (x) 就越接近 K (x)。 研究者表示,由于主要实验结果使用 gzip 作为压缩器,所以这里的 C (x) 表示 x 经过 gzip 压缩后的长度。C (xy) 是连接 x 和 y 的压缩长度。有了 NCD 提供的距离矩阵,就可以使用 k 最近邻来进行分类。 本文方法可以用如下 14 行 Python 代码实现。输入的是 training_set、test_set,两者均由(文本、标签)元组数组和 k 组成。 该方法是 DNN 的简单、轻量级和通用的替代方案。简单在于不需要任何预训练或训练;轻量级在于无需参数或 GPU 资源即可进行分类;通用在于压缩器与数据类型无关,并且非参数方法不会带来潜在的假设。 实验结果 在实验部分,研究者选择多种数据集来研究训练样本数量、类别数量、文本长度以及分布差异对准确性的影响。每个数据集的细节如下表 1 所示。 研究者将自己的方法与 1)需要训练的神经网络方法和 2)直接使用 kNN 分类器的非参数方法,这里有或没有对外部数据进行预训练。他们还对比了其他三种非参数方法,即 word2vec、预训练句子 BERT(SentBERT)和实例长度,它们全部使用 kNN 分类器。 在分布内数据集上的结果 研究者在下表 3 中七个数据集上训练所有基线方法,结果显示,gzip 在 AG News、R8 和 R52 上表现得非常好。其中在 AG News 数据集上,微调 BERT 在所有方法中取得了最佳性能,而 gzip 在没有任何预训练情况下取得了有竞争力的结果,仅比 BERT 低了 0.007。 在 R8 和 R52 上,唯一优于 gzip 的非预训练神经网络是 HAN。在 YahooAnswers 数据集上,gzip 的准确率比一般神经方法低了约 7%。这可能是由于该数据集上的词汇量较大,导致压缩器难以压缩。 因此可以看到,gzip 在极大的数据集(如 YahooAnswers)上表现不佳,但在中小型数据集上很有竞争力。 研究者在下表 4 中列出了所有基线模型的测试准确率平均值(TextLength 除外,它的准确率非常低)。结果显示,gzip 在除 YahooAnswers 之外的所有数据集上都高于或接近平均值。 在分布外(OOD)数据集上的结果 下表 5 中,无需任何预训练或微调,gzip 在所有数据集上优于 BERT 和 mBERT。结果表明,gzip 在 OOD 数据集上优于预训练和非预训练深度学习方法,表明该方法在数据集分布方面具有通用性。 少样本学习 研究者还在少样本设置下比较 gzip 与深度学习方法,并在 AG News、DBpedia 和 SogouNews 上对非预训练和预训练深度神经网络进行实验。 结果如下图 2 所示,在三个数据集上,gzip 的性能优于设置为 5、10、50 的非预训练模型。当 shot 数量少至 n = 5 时,gzip 的性能大幅优于非预训练模型。其中在 AG News 5-shot 设置下,gzip 的准确率比 fastText 高出了 115%。 此外,在 100-shot 设置下,gzip 在 AG News 和 SogouNews 上的表现也优于非预训练模型,但在 DBpedia 上的表现稍差。 研究者进一步在五个 OOD 数据集上研究了 5-shot 设置下,gzip 与 DNN 方法的比较结果。结果显示,gzip 大大优于所有深度学习方法。在相应的数据集,该方法较 BERT 准确率分别增加了 91%、40%、59%、58% 和 194%,较 mBERT 准确率分别增加了 100%、67%、40%、12% 和 130%。 声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。 bian, ji 海报 链接